From NeRFs to Nimble Robots: LERF TOGO's Leap in Zero-Shot Grasping and Semantic Understanding

Michael Rubloff

It’s no secret there are a large amount of use cases for NeRFs. Recently, I took a look at Infinite Realities and examined some of human based ones.
However, today we’re going to look at a new paper that builds on top of one of my favorite papers of this year, Language Embedded Radiance Fields (LERF). As a quick reminder, LERF allows you query a part of the NeRF through text. So, for instance, if you had a NeRF of a kitchen and wanted to know everything in it that could clean up a spill, it would point out paper towels, or a mop, or suggest to be less clusmy. Just kidding about that last one, but you get the sense about how it can be utilized.
Where it gets extraordinarily interesting to me are the larger applications of LERF and there are no shortage of them. So I was thrilled when I saw the title of this paper: Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping.
As it name implies, this takes LERF a step forward with more granularity. For instance, while the computer may be able to correctly identify a mop to help clean a spill, if it isn’t able to tell you where to grasp it, you might end up with wet hands and a scratched up, still wet floor.
Obviously for a human, we would know not to grab a mop by the head, but for all the use cases where we might not interact often— say robotics, it becomes critical. The method behind this is called task-oriented grasping and can be defined by correctly grasping an object based upon the intention and requested outcome of an action.
LERF TOGO outputs a ranking of viable grasps for the requested object and task. From LERF’s standard 3D relevancy map, LERF TOGO then generates a 3D Object Mask. It does this by rendering a top-down view of the scene and queries the object using LERF to obtain a coarse object localization. It then creates a foreground mask by thresholding the first principal component of the rendered DINO embeddings. The relevancy query is constrained to this mask to pinpoint the most relevant 3D point, which is refined to create a complete object mask.
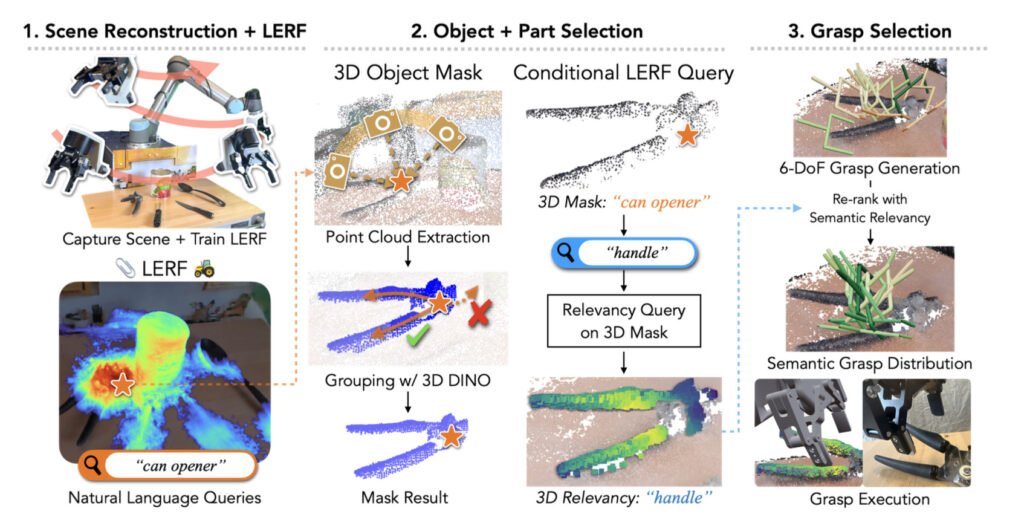
A 3D part relevancy map is then generated with a conditional LERF query over the object part query and the 3D object mask The part relevancy map is used to produce a semantic grasp distribution.
Instead of making a single direct query, LERF-TOGO uses two related queries. Similar to generative modeling where using composed prompts or queries can guide the model towards specific properties or outputs. By combining related queries, it can specify the exact part or attribute of an object that it’s interested in. LERF, by design, is “scale-conditioned.” This means when you give it a query, it doesn’t just look for that object or feature at one fixed size. It searches over multiple scales (or sizes) to find the best representation of that object or feature in the image. In the normal process, LERF would return the relevancy (or match) at the scale where the object or feature has the highest activation or recognition.
With LERF-TOGO, instead of searching everywhere, the search is restricted or “conditioned” to only the points that are within the previously identified 3D object mask. This conditioned search is like telling LERF, “Only look for the handle within the regions we’ve identified”. By doing this, the model will generate a distribution over the object’s 3D structure, indicating the likelihood of each point being the specific desired object part.
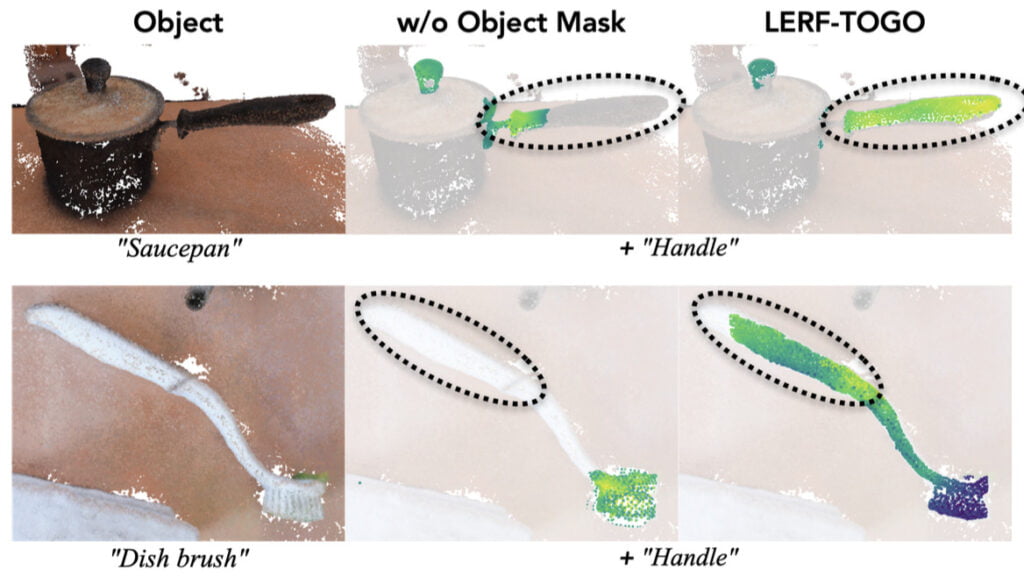
We can see how having the 3D Object Mask dramatically helps the system understand where it should be focusing.
The experiments perform admirably in the first step. It’s able to achieve a 96% on first locating the requested item. However, that’s not necessarily new as that’s what OG LERF does. What really matters is how successful is it in locating the correct place to grab an object? A resounding 82%! But that’s still not the final answer we’re looking for. Now that we know both the object and the location, can a robot actually grab it with the information it has? Yes, it can 69% of the time. Nice. Separately, they ran it through a purely LLM generated prompt and it was successful 96% and 71% of the time identifying and then grasping the correct part.
In order to actually qualify as a successful grasp, the team considers it a success”if it lifts the correct object using the appropriate subpart at least 10cm vertically, and the object remains securely within the gripper jaws throughout.” They found that LERF TOGO is also able to understand more minute details, such as if something is described as “matte” or “shiny”.
Ideally we’re looking for a smaller drop off from the original 96%, as we move through the phases, but this represents tremendous applications for robotics, automation, and maintenance.
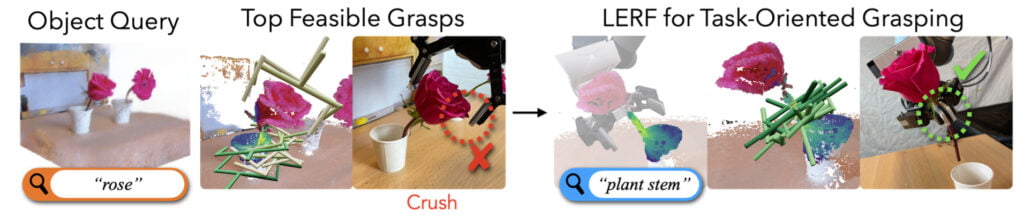
Where LERF TOGO comes up short is differentiating similar looking items on the same object, such as a teapots handle or spout. Clearly, the LLM has never heard the song, I’m a Little Teapot. LERF TOGO also takes a couple of minutes to run in its current form, training to roughly 2K steps. While that may seem fast, it does invalidate high pressure use cases for now, such as the room is on fire, help me put it out. Interestingly, once the NeRF is trained, it only takes LERF TOGO 10 seconds to run. Another place it struggles is where there are several objects overlapping in the foreground, such as flowers in a vase.
The code has not been released yet, but when it is, I think we will see LERF TOGO on nerfstudio.
I strongly believe that LERF will continue to have downstream effects for NeRFs and various industries that begin to grasp (pun intended) what can be done. I’m looking forward to seeing more innovation in semantic processing of NeRFs and will be following this closely.



New to Gaussian Splatting? Start here


