Venturing Beyond Reality: VR-NeRF

Michael Rubloff

The human brain is one of the most powerful cameras in existence, allowing us to see a wide dynamic range, from the darkest shadows to blown-out highlights. To fully believe a space is real, it needs to support that same level of dynamic range.
In the realm of visual media, the rise of consumer virtual reality (VR) headsets marks a significant leap, allowing us to step into worlds where breathtaking photography and video are not just viewed but experienced. Bridging the quality-exploration divide in VR is the aim of groundbreaking systems like VR-NeRF, which promises high-fidelity, free-viewpoint exploration of large, real-world spaces within VR.
It’s been a long-standing question of mine to see what the highest fidelity NeRF can achieve. With papers like VR-NeRF, it’s exciting to see that while they use a setup I will likely not ever be able to afford, creating incredibly high fidelity environments is possible. Their results are not something you will be able to create any time soon, but the potential is thrilling.
I want to be upfront with this paper. Their results are incredible; it’s not something that you will be able to create any time soon. Their set up utilizes 22 Sony A1 cameras AND a 20 A40 workstation to power this.
Let’s delve into the VR-NeRF’s extraordinary capture process. At the heart of the operation is a custom-built rig known as “The Eyeful Tower,” which is central to capturing the thousands of high-resolution images necessary for recreating the intricate detail Meta seeks.
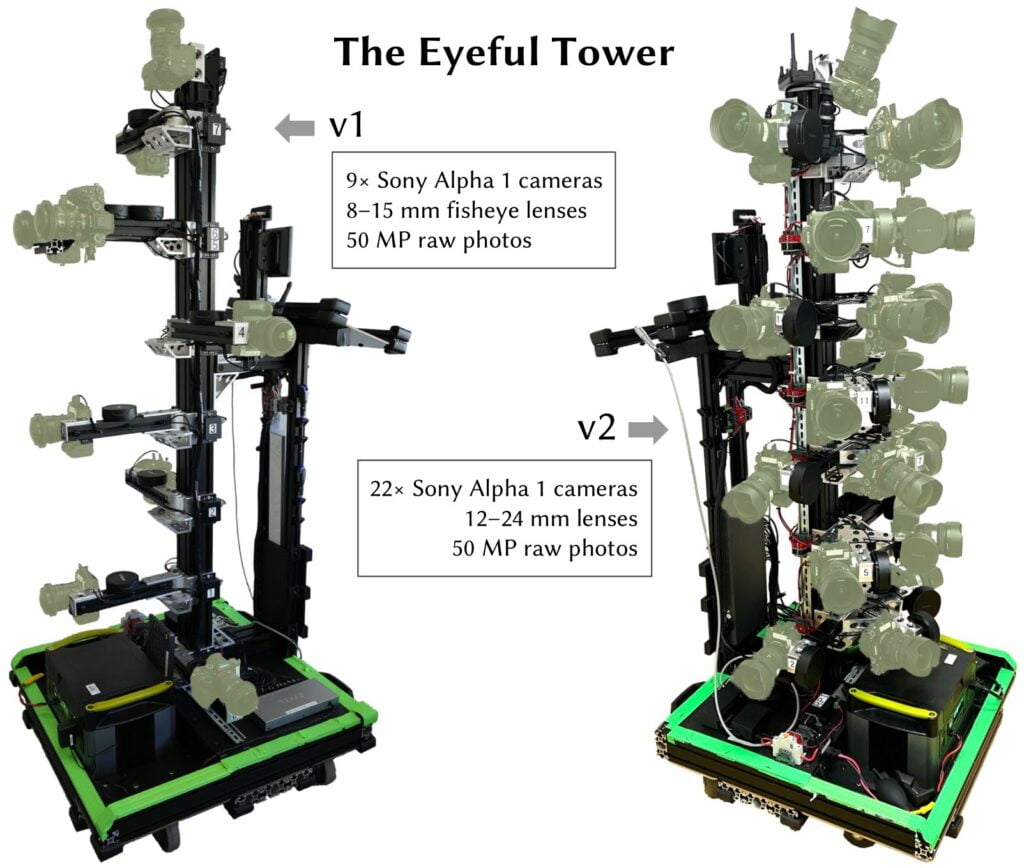
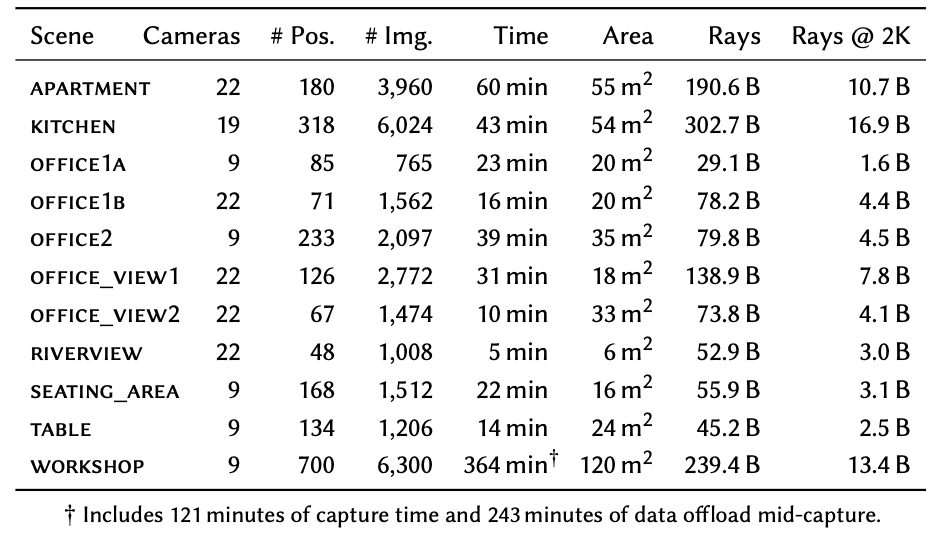
The rig, which has been affectionately named for its comprehensive visual capture ability, employs 21 high-resolution Sony A1 cameras (1 camera is for evaluation). Each camera captures full HDR bracketed shots across nine exposure levels, which are then merged into a single, high-dynamic-range image. These images, from 21 different camera angles for each view, are combined to train the NeRF model. This meticulous process captures up to 6300 photos at a resolution of 5,784×8,660, covering areas as large as 120 square meters and representing up to 303 billion pixels.
Their method is able to achieve 22 stops of dynamic range, which is inordinately high. For comparison, the Sony A1 they use to capture is able to show 14 stops and even that would be considered on the top end of professional cameras. An additional 8 stops is added from the HDR bracketing.
I found it fascinating that their middle shutter speed exposure range was between 1/60th-1/200th of a second and they were still able to produced high fidelity outputs. However, their fastest exposure was 4 stops faster.
I do believe that in larger outdoor real world scenarios, it would be imperative for them to greatly increase their shutter speed. Given their ISO was only set to 500, there is a large amount of room for them to experiment upwards.

To give a high-level view of their capture workflow, they’re taking full HDR bracketed shots, each with nine different levels of exposure and merging those into a single image. This is then combined with 21 other camera angles from that one view, and all the other images from the other views, which is trained into the resulting NeRF.
The capture process itself is meticulously planned and executed. It involves a grid-like positioning of the rig to ensure comprehensive coverage, along with the inclusion of scale bars and color checkers for accuracy. The aim is to capture the scene without altering its elements, ensuring consistent lighting, and minimize shadows.
It is surprising how efficient they are with their captures. Depending on the space, it takes somewhere between 5 minutes to 6 hours. When you take a look at the data as well, you’ll notice that only 2 of the 6 hours were spent capturing, with the other 4 going towards offloading the data. While that’s quite a range, they evaluate spaces as large as 120 meters and as small as 6.

After capture, the images undergo a sophisticated preprocessing procedure. HDR merging, camera calibration, and a thorough assessment of the captured data ensure that the final product is of the highest quality. The datasets captured through this process represent up to 303 billion pixels, covering areas as large as 120 square meters.
VR-NeRF takes inspiration from RAW-NeRF and trains their model using images in a novel perceptually uniform color space that does not require custom losses or tonemapping modules with a Perceptual Quantizer (PQ). Additionally, they utilize level of detail (LOD) methods to reduce geometric and visual complexity, that is tuned specifically for Instant NGP, with the end goal of high-fidelity real-time VR rendering with anti-aliasing. Like many other papers, they built VR-NeRF off of NVIDIA’s Instant-NGP.
Now why might you want to use Level of Detail (LOD)? Its benefit can be seen from the simple fact, that at varying distances, you won’t see certain bits of information. For instance, if you’re twenty feet away from a statue’s inscription, you won’t be able to make out the same level of details as if you were standing directly in front. Often times, LOD can be shown using mip-maps. As its name implies, Mip-NeRF was the first NeRF based paper to introduce Mip-maps, which was then extended with Google’s Zip-NeRF and is also used in Tri-MipRF.
VR-NeRF utilizes mip-mapping to grid features, which effectively teaches distance based features. Interestingly, this dramatically helps with the removal of unintended shadows throughout the capture. It also has the added benefit that it allows the model to better preserve fine details.
Like all things, it does come with a trade off between speed and rendering accuracy. VR-NeRF uses a familiar strategy of using a explicit binary occupancy grid to skip free space and lower the number of sample points. The question then becomes, how do you know which parts of the space isn’t valuable? VR-NeRF uses Cylinder Pruning, which isn’t as complex as it sounds. Basically, it states that anywhere the Eyeful Tower moves in the space, should be considered a 3D cylinder. If that cylinder is able to move through that space, then it must be an open area.

What this leads to is the removal of floaters in front of cameras and more view-consistent models. It speeds up the early stages of training by not querying those areas.
But that’s not all that they do. VR-NeRF actually employs a second pruning strategy, called History Pruning and Grid-Based Pruning. History Pruning looks maximum density observed for each voxel in the occupancy grid during the training process, but the problem is it only looks at rays seen during training. This is where Grid-Based Pruning comes in to evaluate a dense cubic grid inside each voxel of the occupancy grid to estimate the maximum density for each voxel. The pruning stage doesn’t begin until the 100K step mark, which is the same amount of iterations that Nerfacto-Huge takes!
This innovative approach tackles three critical challenges: capturing dense images in large spaces, reconstructing neural radiance fields with high fidelity, and rendering these fields in real-time within a VR environment.
One of their datasets hit a PSNR of 40! I don’t believe I’ve ever seen something score that high before.
This system sets a new standard for virtual reality experiences, allowing for the exploration of large, real-world spaces with unprecedented fidelity. It’s a step towards an immersive future where the lines between the virtual and the real are increasingly blurred, offering an eyeful of possibilities that were once beyond our reach.
The Eyeful Tower rig might not be something we’ll see photographers with on the street corners anytime soon, but the results Meta has achieved are a glimpse of what could be the future of imaging. As VR continues to evolve, we have to wonder, will rigs like the Eyeful Tower become commonplace? Will we see VR experiences that are indistinguishable from reality? Only time will tell, but the future looks bright—and incredibly detailed.
Check out their project page here! They’ve also made their datasets available on their Github.




New to Gaussian Splatting? Start here


