
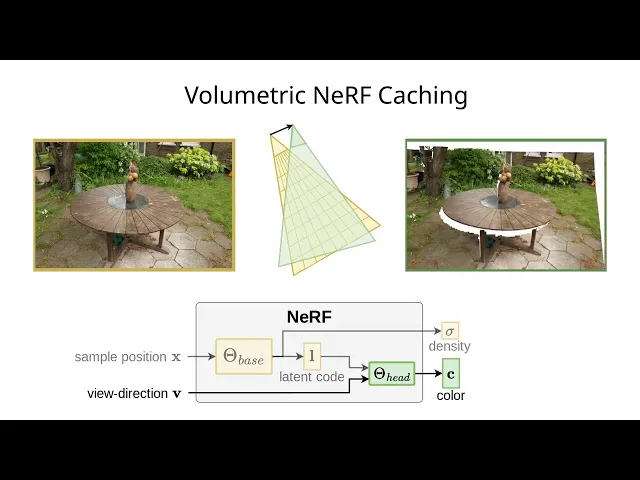

A large criticism of NeRFs is the slower rendering rates compared to Gaussian Splatting. Quietly a couple of papers have been published over the last two months which push NeRFs into real time rates. The computational intensity of NeRFs poses challenges for real-time applications. Addressing this issue, researchers from Graz University of Technology and Huawei Technologies propose an innovative method to accelerate NeRF rendering using frustum volume caching.
This technique significantly enhances both real-time and offline rendering performance, particularly for scenes requiring complex visual effects such as motion blur and depth of field.
The proposed method leverages a temporal coherence technique to cache view-independent latent codes, which are then reused across consecutive frames. This process involves creating a frustum volume cache that stores the outputs of an initial expensive base network (Θbase). These stored values allow for efficient lookups via backward reprojection and trilinear interpolation, significantly speeding up the rendering process by reducing the need to recompute the same values repeatedly.
As the paper’s name implies, they use a sparse frustum volume grid to store latent codes and density values from the base network. This cache is sampled using backward reprojection, enabling efficient reuse of previously computed values.
View-dependent effects are re-evaluated using a smaller head network (Θhead), which processes the interpolated values from the cache. This ensures high-quality rendering while maintaining interactive frame rates. Interpolation of latent codes from a volumetric data structure poses several challenges. Naive linear interpolation of latent codes, which are outputs of a neural network approximating a highly non-linear function, often results in artifacts and degraded image quality. This issue is exacerbated at object boundaries, where the abrupt changes in latent code values can cause visible artifacts such as bright dots or streaks.
To mitigate these interpolation challenges, the researchers propose a novel training scheme to induce spatial linearity into the latent information. By ensuring that the latent codes behave linearly within localized regions, the interpolation process becomes more stable and accurate.
During training, the model generates a random offset for each ray and interpolates each actual sample from two artificially shifted samples along the view ray. This interpolation is performed by evaluating the network at two positions shifted by a random offset and then linearly interpolating the resulting latent codes and densities.

The induced linearity helps the model to learn smooth transitions between samples, significantly reducing artifacts. The researchers found that although inducing linearity slightly degrades image quality metrics, the trade-off is worthwhile given the substantial performance gains and improved rendering quality from the cache. This approach minimizes artifacts and maintains high image fidelity when rendering from the cache.
To further enhance the efficiency of the caching mechanism, the researchers introduced a view-dependent cone encoding technique. This method produces view-dependent latent codes that encode the viewing information for a cone around the cached view direction. By doing so, it reduces the amount of information each latent code needs to store, as it only has to represent the viewing direction within a specific cone rather than the entire 360-degree range.
During training, the model is provided with multiple view directions within the cone to learn how to generate latent codes that can be re-evaluated from slightly different viewpoints. This approach allows the head network (Θhead) to quickly adapt to small changes in view direction without significant computational overhead. Consequently, the view-dependent cone encoding technique helps maintain high rendering quality while further reducing memory and processing requirements.
All of these combine to max out the cache lookup speed, while reducing cache size, and speed up the cache initialization. The frustum volume caching technique significantly accelerates both real-time and offline NeRF rendering. For real-time applications, the method achieves speed-ups of up to 4.8× compared to existing NeRF models, enabling interactive frame rates without compromising quality. For offline rendering, particularly in scenarios involving complex visual effects, the method offers up to 2× speed-up, making it highly suitable for high-quality video sequences.
An interesting note, I do believe that by continuing to optimize tiny cuda nn, there are still significant speed ups to be had. Should NVIDIA release a new version of this, I would be curious to see if it would solve the problem of real time rendering in NeRFs entirely.
The code for Frustum Volume Caching has already been released and it comes with an MIT License! It can be accessed from their Github page and more information about the method can be found on their project page.




New to Gaussian Splatting? Start here


