

We continue our SIGGRAPH Asia series chatting with Meta’s Codec Avatars Lab team about their groundbreaking paper: “VR-NeRF: High-Fidelity Virtualized Walkable Spaces’’.
They showcase advancements in Meta’s high-resolution 3D real-time rendering captured with 22 cameras on the “Eyeful Tower” camera rig. We have previously covered the VR-NeRF paper but were keen on the backstory of probably the highest resolution real-time NeRF today. We extend our gratitude to the team for sharing insights into their innovative work.

Q: Could you start by introducing your team and its focus within META’s Avatar’s Lab?
A: Within the Codec Avatars Lab, our team is dedicated to environment rendering, handling spaces and related aspects. We are here with Linning Xu who presented “VR-NeRF: High-Fidelity Virtualized Walkable Spaces” in the session today, Christian Richardt and Vasu Agrawal from Meta in the USA. Surprisingly, our team is quite small in the grand scope of things – only a couple of researchers, typically two or three, along with some engineers managing all the necessary systems.
Our focus on environment rendering is a specialized and essential component of the larger lab. We think the environments are a core component of a “complete” telepresence experience.
Q: Impressive work. Moving on to your camera rig and resolution considerations, what did it take to capture the probably largest resolution real time NeRF today?
A: We have built two versions of the Eyeful camera rig, both intentionally without 360° coverage, offering a range of 240 to 270 degrees. So enough space that you could stand behind it. The most recent version of our “Eyeful Tower” capture rig has 22 50-megapixel cameras, so our captures contain many billions of pixels. The captured images have a resolution of around 50 pixels per degree, which closely matches what the human eye can see. No existing NeRF model, including ours, can handle that right now. Though all existing headsets and models struggle with the full 8K resolution, capturing and releasing this data allows for plenty of headroom for future research.
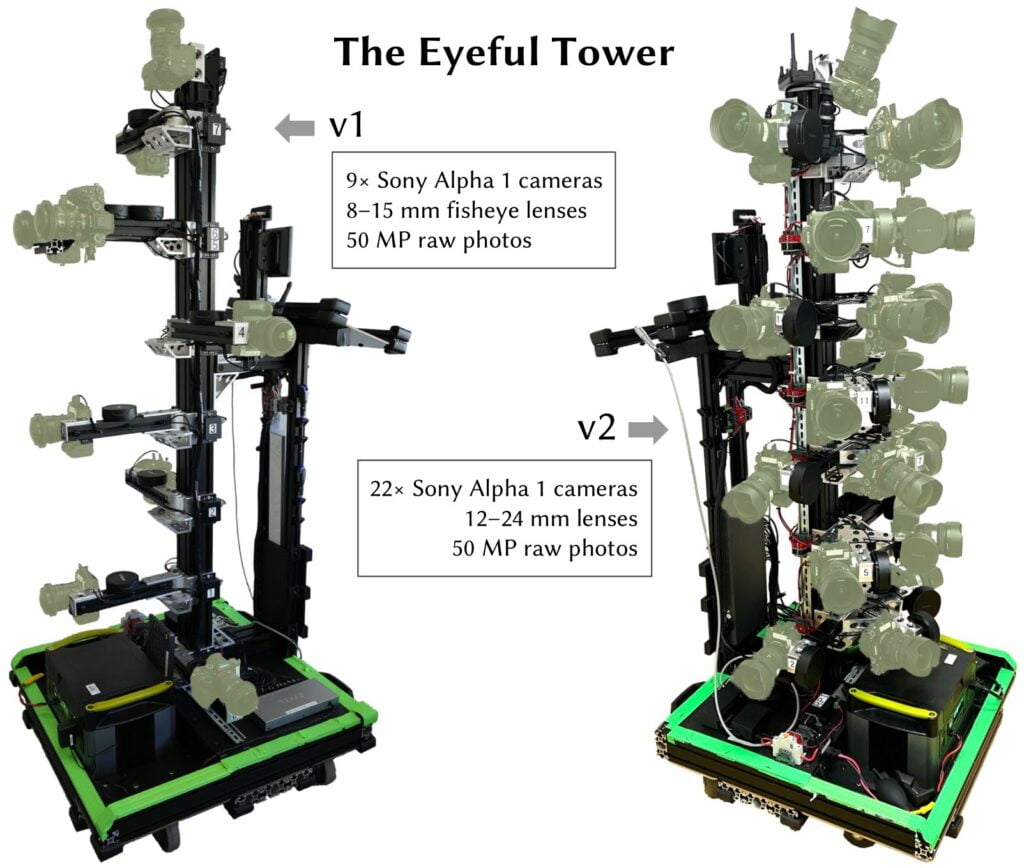
We have also faced some challenges with changing lighting when capturing scenes… Even in the five minutes to two hours that it takes to do a capture, the sun moves a little bit and causes different shadows. And the rig casts different shadows on the walls as you are moving around the space. We specifically added strategies in VR-NeRF to handle those things to not cause artifacts in our result. We did not yet try capturing data outdoors as the rig’s wheels are not suitable for that, but in theory it should work.
Q: Switching gears, could you tell us more about your ongoing efforts in code release and standardization?
A: In good news, the “Eyeful Tower” dataset will soon be supported in nerfstudio. All of the 11 scenes in the dataset are from our Pittsburgh office, except for the one labeled “apartment”. However, our implementation is closely integrated with our internal infrastructure and tied to an internal training framework, which makes it challenging to extract and release our code. Instead, we are working to integrate our dataset into the public nerfstudio framework, which will be much easier for others to build on.
There are no existing datasets that are high dynamic range at room scale, which are captured at this high resolution. That is really where we want virtual reality to be. We want people to benchmark against our “Eyeful Tower dataset” and be able to test against something that captures those details.
We also found the support for High dynamic range (HDR) images to be lacking in most NeRFs, which would not be able to learn so many nuanced details in these images. We took an industry standard for HDR video, the perceptual quantizer (PQ), and extended it to NeRFs. This makes it possible to learn the full dynamic range of HDR images with our VR-NeRF model.
Q: That is great to hear. Your discussion on standardization is quite relevant. Is this the moment to standardize a NeRF format?
A: I think it is probably too early for a NeRF model standard. But the existence of nerfstudio is a testament to the parts of NeRF and methods that are stable: there is plenty of standardization. If you look at nerfstudio, basically you can replace the model code and everything else stays the same: the cameras, all the data loading, all the rendering, all of that. They did that fundamentally right: It gives you the flexibility around the research to make the model whatever you want, but the infrastructure stays the same. And building a lot of tooling around that interface makes a lot of sense.
The black box that goes in the middle of that interface is very much up in the air and not really standardized yet or not really converged yet.
But this structure is a great place to be and, internally, we have the same thing for all of our papers and all of our projects. VR-NeRF and our other NeRF work can use the same back and front end, and then just the model changes.
Q: Do you have active user research, and how does it fit into your evolving work?
A: We are considering more active user research as our results become more compelling. It is a balance; when results are photorealistic and show promise, investing in user studies becomes worthwhile.
Do we have time for it? Can we afford the trade-off against the other things that we’re working on? There’s so much to do. And especially with the pace of the field, right? So much stuff, Gaussian splatting, it came out so quickly. It came out and the conference missed it. But obviously there is a lot of interest in this work, also in our lab.
Q: The rapid evolution of the field is undoubtedly a challenge. How have you managed to keep up with the fast-paced advancements?
I think the answer is you adopt the attitude that you are never gonna keep up with all of it. And then you just hope that the best work surfaces to the top: about three papers make it through for me a day. But even reading three papers a day is hard. Like reading them thoroughly? I really can not do three papers a day thoroughly.

Q: What are your next goals for the project?
A: Well, speed and quality. 3D Gaussian splatting is still about 20 times faster than our VR-NeRF implementation. But it also does not really achieve the quality on our data. We have competitive frame rates, not surpassing, but our quality is substantially better.
However, Gaussian splatting does not handle things like minor lighting changes throughout the scene yet. I guess everybody is also looking at hybrid NeRF methods for the step up in speed. Volumetric methods that have sampling bounds near surfaces, is really the gist of hybrid NeRFs, to focus the rendering effort where it is most needed. So, because you have a bounding mesh, you can also use physics with it. I think it is a lot better and fits better with existing composition and creation tools, but it is still a bit too early to commit to.
Q: How do you see the potential applications of NeRF-like methods in gaming and film? Is there a future without polygons?
A: I am not qualified to answer that, I guess nobody knows at this point. Polygons are so fast to render. They are because we spent more than 25 years baking them: they are baked into silicon. But there are scene objects like carpet, for example, that are a mess with just polygons. Will this specific application be enough to justify companies building custom silicon in a chip that will ship to hundreds of millions of people?
In real-time rendering, you need to take advantage of the hardware. So really what it comes down to is: do we expect there will be support from the hardware vendors? The time budget you have for backgrounds and environments is just a tenth of a frame time. I am not convinced the solution is just a hardware thing: we are 10 maybe 15x away from getting hardware down to the point of it runs in a game’s environment time budget.
And then the question is also scene editability: You want to not just look at a table but maybe also move it around. You want to build something on that table or put stuff on top of the table.
It seems like a lot of the interesting innovations lately have been around areas where you can afford more mistakes rather than big films or games. Well, I mean where a mistake is not critical.
(Note: The interview format is a condensed representation for clarity.)

Links



New to Gaussian Splatting? Start here





