
SplaTAM: SLAM with Speed, Precision, and Gaussian Splats

Michael Rubloff

In the evolving landscape of robotics and vision systems, the quest for a method that not only navigates but also reconstructs unknown environments with precision and efficiency has been relentless. This quest brings us to SplaTAM (Splat, Track & Map), a novel approach in Simultaneous Localization and Mapping (SLAM) that significantly deviates from traditional methods. By incorporating 3D Gaussian Splatting into its volumetric representation, SplaTAM marks a new era in tackling complex, unstructured environments where previous approaches have struggled.
They say in film that good lighting is where you never realize the scene is being artificially lit. In radiance fields, one of the most challenging things to capture are featureless white rooms, where there’s a lack of identifiable objects and barriers to latch onto.
Just like good lighting, you wouldn’t realize that from the demos that the team showcased. This seemingly boring room, is actually an expression that truly is not easy to capture. I have tried it repeatedly, and have never come up with a high quality output
At its core, SplaTAM integrates differentiable rendering with a 3D Gaussian-based radiance field, an approach unprecedented in dense SLAM. This integration weaves together several innovations into a cohesive and powerful method.
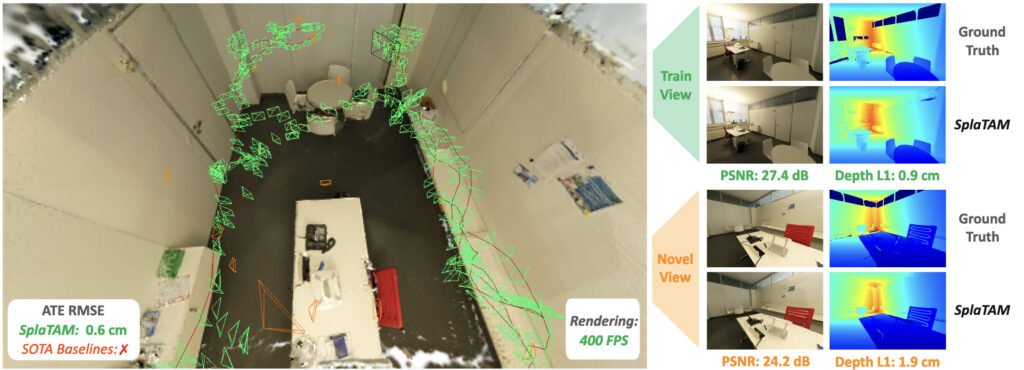
The primary breakthrough of SplaTAM lies in its unprecedented rendering speed—up to 400 FPS. This speed is a game-changer, enabling real-time optimization and dense photometric loss application in SLAM. It’s a stark contrast to previous methods, which were bogged down by the computational demands of efficient rendering.
The explicit spatial mapping capability of SplaTAM is a critical component. By clearly defining the mapped areas of a scene, it ensures precise camera tracking. This is a significant leap from implicit map representations, which often suffer from global changes during optimization and lack this level of clarity.
The method’s map is both scalable and editable, thanks to its explicit volumetric representation. This flexibility in expanding the map capacity and editing parts of the scene without sacrificing photorealism sets SplaTAM apart from its predecessors, especially implicit approaches that lack these capabilities. A standout feature of SplaTAM is its efficient optimization. With a direct gradient flow from the parameters to the rendering, the process becomes simpler and more intuitive, a stark difference from the complex pathways in neural-based representations.
In rigorous testing across various datasets like ScanNet++, Replica, and TUM-RGBD, SplaTAM consistently outshines existing methods in camera pose estimation and map construction. It particularly excels in handling large motions between camera positions and thrives in texture-less environments, where traditional methods falter. The superior rendering quality in training views and novel-view synthesis further underscores its robust reconstruction capabilities.
SplaTAM is available to try it yourself, through their Github. In order to capture a dataset with an iPhone, you will need the NeRFCapture App. It will also work on any other LiDAR equipped Apple device, such as the iPad Pro. It’s crazy to believe it was back in April that Jonathan Stephens did a livestream of how to use NeRFCapture. The SplaTAM Github page has great instructions how to do the rest.
SplaTAM unique integration of 3D Gaussian Splatting with SLAM opens a new chapter in the field, offering a robust framework for scene understanding and robotics. The future of SplaTAM lies in scaling to larger scenes, improving its resilience to motion blur, and reducing dependency on known camera intrinsics. In essence, SplaTAM paves the way for more sophisticated, efficient SLAM systems, ushering in a new era of possibilities in autonomous navigation and robotics.
Additionally, this is V1 of SplaTAM. I am told there there are some really exciting improvements and functionalities that will be supported in V2, which might be coming sooner than you would imagine.




New to Gaussian Splatting? Start here


