4 Input View NeRFs with DINER (Depth-aware Image Neural Radiance Field)

Michael Rubloff

Earlier today, I was impressed with the output of 12 images coming from a webcam. It seems as though the bar has been raised with DINER, Depth-aware Image Neural Radiance Fields.
They're able to effectively generate human heads through just 4 inputs. Some of the demonstrations remind me of DroNERF, which advocated for ideal camera capture paths.
DINER is built on top of Pixel NeRF, which specializes in creating NeRFs from one or a small collection of images. Funnily enough, most of the authors of Pixel NeRF are now at Luma (Alex Yu, Matt Tancik, Anjgoo Kanazawa).
Where the methods begin to differ is that DINER additionally employs a Depth Generator in addition to an Image Encoder to generate the Feature Maps of a scene. This Depth Generator helps bring the Depth Standard Deviation as well as the Depth Expectation Value into the scene.
It's at this point where we see the ray marching hallmark of NeRF become incorporated. In other words, a ray is cast through the space and at given points, samples are taken, ascribing each pixel's color output depending on the viewing angle.
Then in this sampling phase, the depth projection value is taken into consideration with that given sample. This gives an additional resource to the method to build off of. The other data points that are examined are the Interpolated Feature, the Sample Location, the Ray Direction, the Intermediate Feature, and finally the added Depth Deviation. These together creates the color as well as the optical density of the sample.
With a process like this, sampling can take a bit of time, so they introduce a method improve efficiency using those predicted depth maps. DINER concentrate on the points where the ray meets the surface of the object. For instance, with a human head, it might be the nose. This is because these areas have the greatest effect on the correct color to display.
While that makes sense, how does it know what's an object and what's another part in the scene? These depth and standard deviation map, create a probability curve to the areas that might be an object. This is extended to every sampled point, for each individual view, allowing for uniformity across the scene. Kind of crazy, right?
But that's just the start. They use max pooling to obtain View Independent Surface Likelihoods and then flag samples with the highest values. Once that first sample area has been found, they calculate Occlusion Aware Surface Likelihoods, create another probability distribution curve, and then resample additional points contained in that area. This results in even more accurate representations in high importance areas. It has a further effect in thin surfaces, for say an ear lobe or fingers.
Given the sparse number of input data, it's inevitable and expected that there will be artifacts, especially where the cameras didn't capture. However, the research team has employed some methods to address that. Instead of using border padding after feature map generation, they use border padding prior to their generation. This actually ends up extending the size of the feature grids and provides more information for DINER to pull from.
It's important to note DINER is not reserved for human head reconstruction. They also demonstrate brick reconstruction and showcase clean fidelity. An additional example is of some home goods, with the text reading out cleanly.

The code is publicly available right now, for those who would like to try it. I've been fascinated by these sparse input NeRF methods and DINER showcases another step forwards to making really clean outputs. I still believe that we are nowhere close to having NeRFs feature in video conferencing or competing with Apple or Google, but this is another reminder that progress is being made and that it's probably happening faster than you imagine.



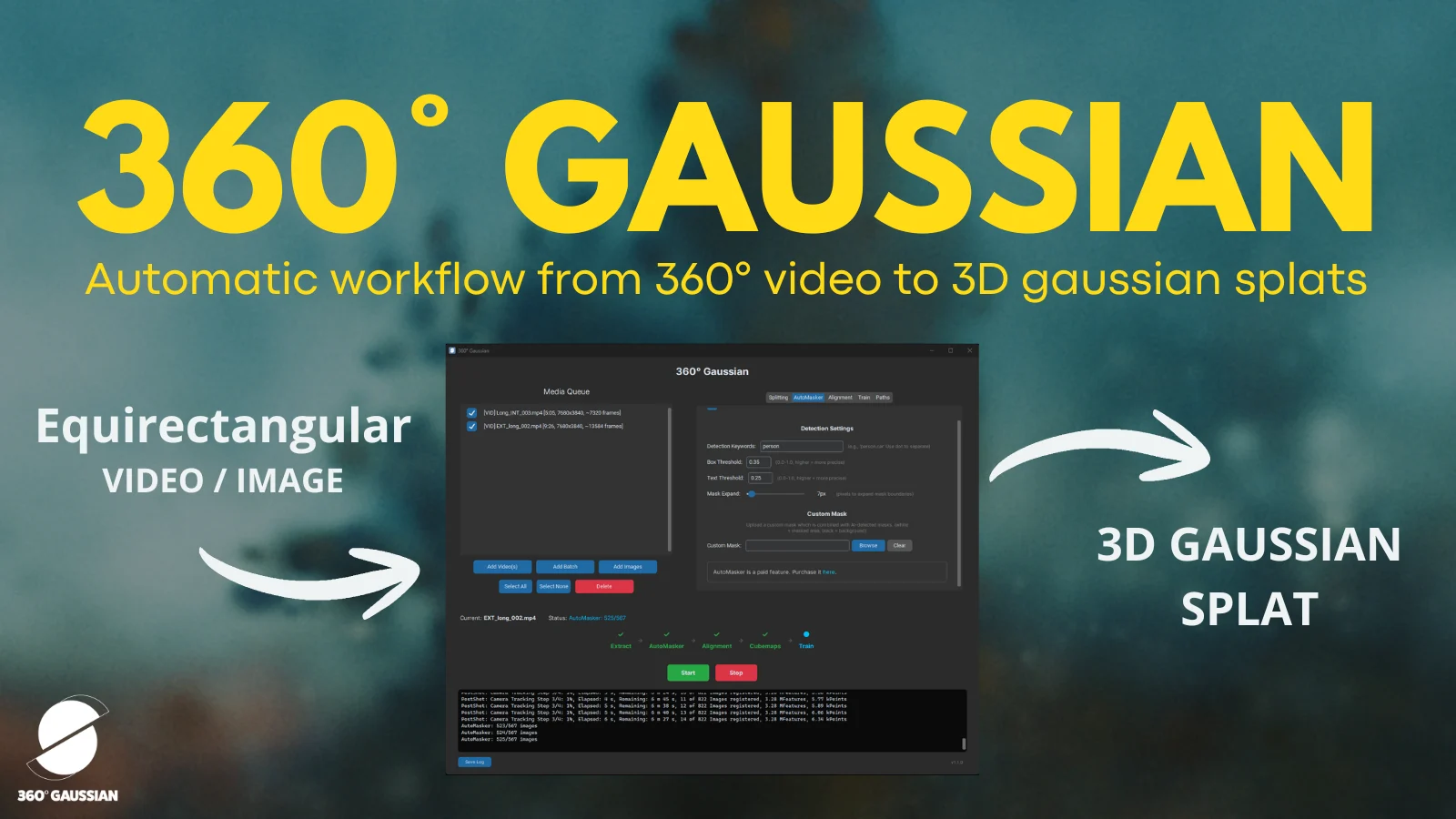
New to Gaussian Splatting? Start here


